Staging and File System Choice
Overview
Teaching: 20 min
Exercises: 20 minQuestions
What is a file system?
What is a distributed file system?
How do you optimize file system on Mana?
Objectives
Understand general file system and distributed file system concepts.
Being able to stage files on Mana lustre scratch.
What is a file system?
The term file system is ubiquitous among operating systems. At some point in time, you may have had to format a USB flash drive (SD card, memory stick) and may have to choose between different file systems such as FAT32 or NTFS (on a Windows OS), exFat or Mac OS Extended (on a Mac).
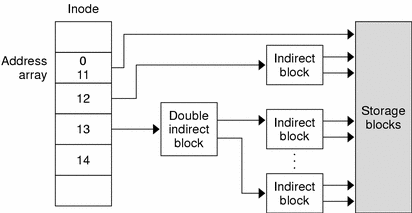
File systems are ways in which operating systems organize data (i.e. documents, movies, music) on storage devices. From the storage device hardware perspective, data is represented as a sequence of blocks of bytes, however that by itself isn’t useful to regular users. Regular users mostly care about file and directory level abstraction and rarely work with blocks of bytes! Luckily, the file system under the hood handles the organization and locating logic of these blocks of bytes for the users so that you can run your favorite commands (e.g., ls) and applications. For example in a Linux file system, “file” information is stored in an inode table (illustrated in figure above) as sort of a lookup table for locating corresponding blocks of a particular file on disk. Located blocks are combined together to form a single file which the end user can work with.
What is a distributed file system?
On a cluster, blocks of data that make up a single file are distributed among network attached storage or NAS devices. Similar principles apply here, the goal of a cluster file system is still to organize and locate blocks of data (but across network!) and present them to the end user as one contiguous file. One main benefit of stringing storage devices together into a network connected cluster is to increase storage capacity beyond what a single computer can have. Imagine working with 100 TB files on your laptop. Of course, the storage can be shared with different cluster users further increasing utilization of these storage devices.
On Mana, the two main supported file systems are Network File System (NFS) and Lustre. Mana users have two special folders called lus_scratch and nfs_scratch where they can temporarily store data on the cluster. Note that the scratch folders will be purged after some period of time, please save your important files into your home directory.
Locate Lustre and NFS File System Scratch On Mana
Let’s locate our lustre and nfs scratch folder. First create a new cell in our Jupyter Lab Notebook after the first cell Paste the code into the cell and run. The pwd command will print where you are in the directory tree and it should be something like “/home/username The ls command will print files and directory that are available in your home/username directory. You should see “lus_scratch” and “nfs_scratch” listed in the print out. Note that the ‘!’ symbol below allows us to execute terminal commands in our Jupyter Lab Notebook cell.
!pwd !ls
Lustre File System.
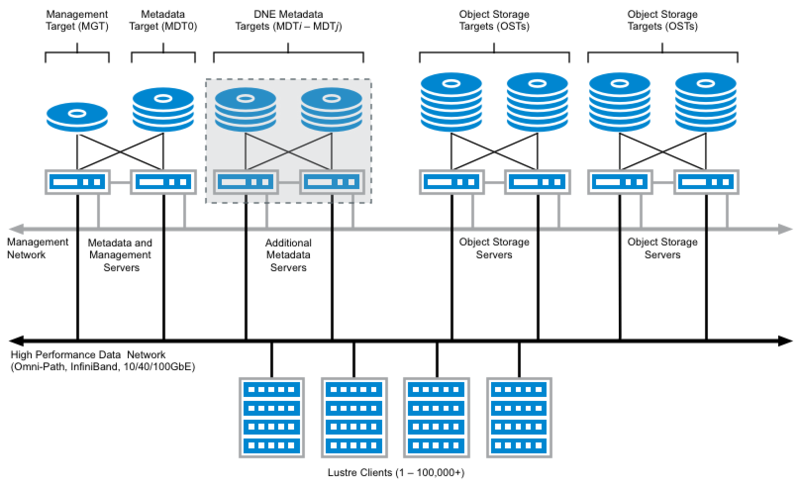
Lustre is a parallel distributed file system, where file operations are distributed across multiple file system servers. In Lustre, storage is divided among multiple servers allowing for ease of scalability and fault tolerance. This file system is great for high speed read/write performance.
NFS File System
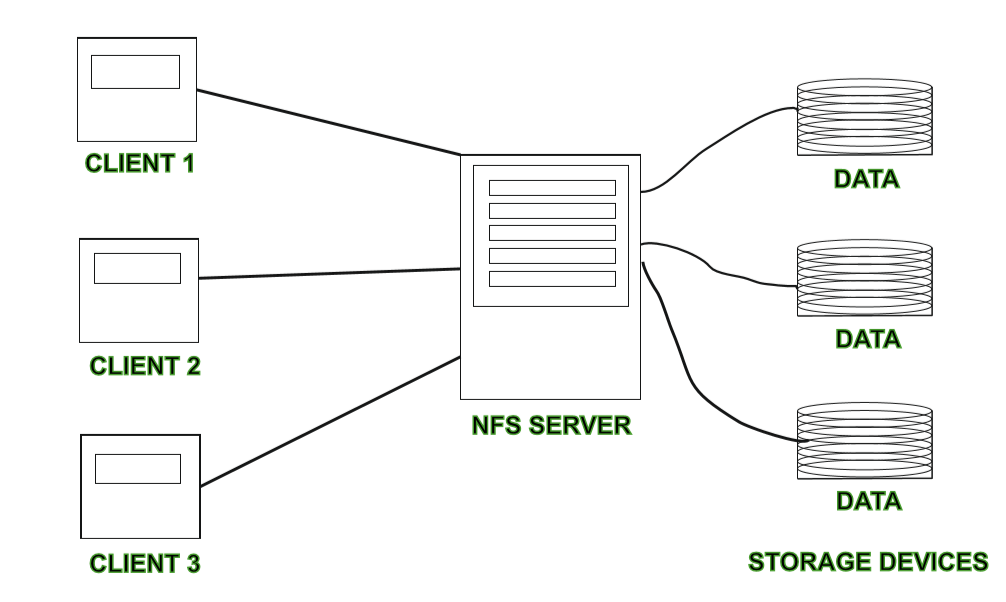
NFS is a single server distributed file system where file operations are not parallel across servers but a single server serves requests to the cluster. NFS is an older technology and has the advantage of having gone through the test of time and is trusted among cluster architects.
Choosing the Right File System For Performance
Depending on the user’s need, different file systems are optimized for different purposes. One may be optimized for random access speed, one with error correcting capability, or one with high redundancy to prevent loss of data. For this workshop, we will focus on disk random access speed Mana cluster.
On Mana we have 3 locations for file storage: “home/user”, “lus_scratch”, and “nfs_scratch” folders available to us. On Mana, our “home/user” directory resides on an NFS file system server. Though “home/user” is great for storing our files on the cluster, it’s serverly lacking in read/write performance. For the best performance (read/write speed) we will mostly want to use “lus_scratch”. As discussed above, the reason is because Lustre file system distributes workload accross multiple meta servers, while NFS is a single server file system. In addition, Mana Lustre file system is configured with solid state drives while NFS file system is configured with hardrives, improving Mana lustre file system read/write speed further.
Solid State Drive vs. Hardrive Performance
Solid state drives can read up to 10 times faster and writes up to 20 times faster than hard disk drive. You can read more about it here.
List Usage Information
On Mana, there’s a command that lists disk usage on the cluster. Create a new cell below our previous block. Paste the code into the cell and run. You should see a table that lists disk space used and remaining space.
!usage
Simulating Read/Write Load
Let’s compare read/write speed between the 2 file systems. In new cells, define a write function that simulates writes to our file system and define a read function that simulates read from our file systems. Note that internally, file write operation is buffered to memory, this is the reason why we need to flush our buffer so that actual writes to disk happens.
def write_large_file(path): with open(path, 'w') as f: for i in range(1000000): f.write(str(i)) f.flush() def read_large_file(path): with open(path, 'r') as f: for i in range(1000000): f.read(1)
Timing Read/Write Operations
Now that we have defined our read/write functions, let’s profile them. In new cells, call our read / write functions from our “lus_scratch” directory. Similarly call our read/write functions from our “home” directory (remember that home directory resides in Mana NFS file system servers). To time the cells, we can call “%%time” at the beggining of our cells. This is a special command in Jupyter Lab Notebook that allows us to time execution time of a cell.
%%time write_large_file("./lus_scratch/large_file.txt")%%time read_large_file("./lus_scratch/large_file.txt")%%time write_large_file("./large_file.txt")%%time read_large_file("./large_file.txt")
Read Speed Improvement Performance
From the challenge, we may notice a very small improvement in read performance. This is most likely due to the fact that we do sequential reads (read more about that here) and also the fact the created file is too small to show the difference in improvement.
Optimizing Our Deep Learning Code
We can optimize our Deep Learning Jupyter Lab Notebook further by utilizing “lus_scratch” folder. Instead of reading and writing training data from our home directory, we’re going to instead work from the “lus_scratch” directory.
Stage Training Files
We will now make a copy of the training data into the “lus_scratch” directory. Create a new cell in our Jupyter Lab Notebook. Paste the code below into the cell. Update the path so that the data is save into our “lus_scratch” directory. You should see a print out of the with “dataset_cifar10.hdf5”.
# Stage files onto luster directory. with h5py.File('./lus_scratch/dataset_cifar10.hdf5', 'w') as hf: dset_x_train = hf.create_dataset('x_train', data=x_train, shape=(50000, 32, 32, 3), compression='gzip', chunks=True) dset_y_train = hf.create_dataset('y_train', data=y_train, shape=(50000, 1), compression='gzip', chunks=True) dset_x_test = hf.create_dataset('x_valid', data=x_valid, shape=(10000, 32, 32, 3), compression='gzip', chunks=True) dset_y_test = hf.create_dataset('y_valid', data=y_valid, shape=(10000, 1), compression='gzip', chunks=True) !ls "./lus_scratch/"
Update Data Generator File Path
Now that we have successfully staged our training data to the “lus_scratch” directory, let us now update the data path for our data generator. Find where the data is loaded, the code in the cell should look like the code below. Once the cell is updated, run the cell.
filename = "./lus_scratch/dataset_cifar10.hdf5" batchsize = 250 data_train_lus = DataGenerator(filename, batch_size=batchsize, test=False) data_valid_lus = DataGenerator(filename, batch_size=batchsize, test=True, shuffle=False)
Rerun The Model With The Updated Data Generator
Let’s rerun our model with the new data generator objects. Use the GPU version of the training code similiar to below. Run training step of the model. Compare the training time. Note: As we’ve seen previously, both file systems are comparable in read speed for small data sets. Here, we may not see a huge difference since we’re mostly performing read. With bigger data sets, such as “cifar100” data set, differences in read speed will be more noticable.
from tensorflow.keras.models import clone_model new_model = clone_model(model) opt = keras.optimizers.Adam(learning_rate=0.001) new_model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) with tf.device('/device:GPU:0'): new_history = new_model.fit(data_train_lus, epochs=10, verbose=1, validation_data=data_valid_lus)
Key Points
File system is a way in which operating systems organize data on storage devices.
Distributed file system organizes data accross network attached storage devices.
Distributed file system has the advantage of supporting larger scale storage capacity.
Mana supports lustre and NFS file systems.
Lustre on Mana is setup with solid state drives.
NFS on Mana is setup with spinning drives.